Filter by topic and date
How to Read an RFC
- Mark Nottingham QUIC Working Group Co-Chair
9 Sep 2018
For better or worse, Requests for Comments (RFCs) are how we specify many protocols on the Internet. These documents are alternatively treated as holy texts by developers who parse them for hidden meanings, then shunned as irrelevant because they can’t be understood. This often leads to frustration and – more significantly – interoperability and security issues. However, with some insight into how they’re constructed and published, it’s a bit easier to understand what you’re looking at.
Here’s my take, informed from my experiences with HTTP and a few other things.
Where to start?
The canonical place to find RFCs is the RFC Editor Web Site. However, as we’ll see below, some key information is missing there, so most people use tools.ietf.org.
Even finding the right RFC can be difficult since there are so many (currently, nearly 9,000!). Obviously you can find them with general Web search engines, and the RFC Editor has an excellent search facility on their site.
Another option is rfc.fyi, which I put together to allow searching RFCs by their titles and keywords, and exploration by tags.
It’s no secret that plain text RFCs are difficult to read bordering on ugly, but things are about to improve; the RFC Editor is wrapping up a new RFC format, with much more pleasing presentation and the option for customisation. In the meantime, if you want more usable RFCs, you can use third-party repositories for selected ones; for example, greenbytes keeps a list of WebDAV-related RFCs, and the HTTP Working Group maintains a selection of those related to HTTP.
What kind of RFC is it?
All RFCs have a banner at the top that looks something like this:
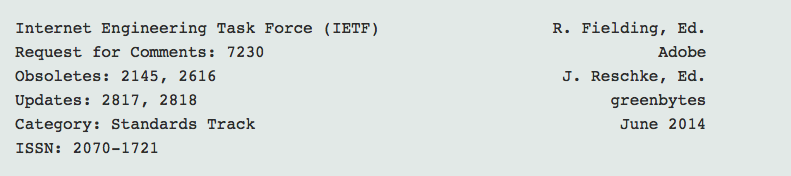
At the top left, this one says “Internet Engineering Task Force (IETF)”. That indicates that this is a product of the IETF; although it’s not widely known, there are other ways to publish an RFC that don’t require IETF consensus; for example, the independent stream.
In fact, there are a number of “streams” that a document can be published on. Only the IETF stream indicates that the entire IETF has reviewed and has declared consensus on a protocol’s specification.
Older documents (before about RFC5705) say “Network Working Group” there, so you have to dig a bit more to find out whether they represent IETF consensus; look at the “Status of this Memo” section for a start, as well as the RFC Editor site.
Under that is the “Request for Comments” number. If it says “Internet-Draft” instead, it’s not an RFC; it’s just a proposal, and anyone can write one. Just because something is an Internet-Draft doesn’t mean it’ll ever be adopted by the IETF.
Category is one of “Standards Track”, “Informational”, “Experimental”, or “Best Current Practice”. The distinctions between these are sometimes fuzzy, but if it’s produced by the IETF (see above), it’s had a reasonable amount of review. However, note that Informational and Experimental are not standards, even if there’s IETF consensus to publish.
Finally, the authors of the document are listed on the right side of the header. Unlike in academia, this is not a comprehensive list of who contributed to the document; often, that’s done near the bottom in an “Acknowledgments” section. In RFCs, this is literally “who wrote the document.” Often, you’ll see “Ed.” appended, which indicates that they were acting as an editor, often because the text was pre-existing (like when an RFC is revised).
Is it current?
RFCs are an archival series of documents; they can’t change, even by one character (see the diff between RFC7158 and RFC7159 for an example of this taken to the extreme; they got the year wrong ;).
As a result, it’s important to know that you’re looking at the right document. The header contains a couple of bits of metadata that help here:
- Obsoletes lists the RFCs that this document completely replaces; i.e., you should be using this document, not that one. Note that an old version of a protocol isn’t necessarily obsoleted when a newer one comes out; for example, HTTP/2 doesn’t obsolete HTTP/1.1, because it’s still legitimate (and necessary) to implement the older protocol. However, RFC7230 did obsolete RFC2616, because it’s the reference for that protocol.
- Updates lists the RFCs that this document makes substantive changes to; in other words, if you’re reading that other document, you should probably read this one too.
Unfortunately, the ASCII text RFCs (e.g., at the RFC Editor site) don’t tell you what documents update or obsolete the document you’re currently looking at. This is why most people use the RFC repository at tools.ietf.org, which puts this information in a banner like this:

Each of the numbers on the tools page is a link, so you can easily find the current document.
Even the most current RFC often has issues. In the tools banner, you’ll also see a warning on the right that “Errata Exist” along with a link to Errata above it.
Errata are corrections and clarifications to the document that aren’t worthy of publishing a new RFC. Sometimes they can have a substantial impact on how the RFC is implemented (for example, if a bug in the spec led to a significant misinterpretation), so they’re worth going through.
For example, here are the errata for RFC7230. When reading errata, keep their status in mind; many are rejected because someone just misread the spec.
Understanding context
It’s more common than you might think for a developer to look at a statement in an RFC, implement what they see, and do the opposite of what the authors intended.
This is because it’s extremely difficult to write a specification in a manner that can’t be misinterpreted when reading it selectively (as is the case with any holy text).
As a result, it’s necessary to read not only the directly relevant text but also (at a minimum) anything that it references, whether that’s in the same spec or a different one. In a pinch, reading any potentially related sections will help immensely, if you can’t read the whole document.
For example, HTTP message headers are defined to be separated by CRLF, but if you skip down here, you’ll see that “a recipient MAY recognize a single LF as a line terminator and ignore any preceding CR.” Obvious, right?
It’s also important to keep in mind that many protocols set up IANA registries to manage their extension points; these, not the specifications, are the sources of truth. For example, the canonical list of HTTP methods is in this registry, not any of the HTTP specifications.
Interpreting requirements
Almost all RFCs have boilerplate that looks something like this near the top:

These RFC2119 keywords help define interoperability, but they also sometimes confuse developers. It’s very common to see a specification say something like:

This requirement is placed upon a protocol artefact, the” Foo message”. If you’re sending one, it’s pretty clear it needs to not contain a Bar header; if you include one, it won’t be a conformant message.
However, the behaviour of the recipient is much less clear; if you see a Foo message with a Bar header, what do you do?
Some developers will reject a message that contains it, even though the specification says nothing about doing so. Others will still process the message, but strip the Bar header, or ignore it – even when the spec explicitly says that all headers need to be processed.
All of these things can – unintentionally – cause interoperability issues. The correct thing to do is to follow normal processing for the header unless there’s a specific requirement to the contrary.
That’s because in general, specifications are written so that behaviours are overtly specified; in other words, everything that is not explicitly disallowed is allowed. Therefore, reading too much into specifications can unintentionally cause harm, since you’ll be introducing new behaviours that others will have to work around.
In an ideal world, the specification would be defined in terms of the behaviours of those who handle the message, like this:

Absent that, it’s best to look for more general advice about error handling elsewhere in the specification (e.g., HTTP’s Conformance and Error Handling section).
Also, keep in mind the target of requirements; most specifications have a highly developed set of terms that they use to distinguish between different roles in the protocol.
For example, HTTP has proxies, which are a kind of intermediary, which implement both a client and a server (but not a User-Agent or an origin server); they need to pay attention to requirements targeted at all of those roles.
Likewise, HTTP distinguishes between “generating” a message and merely “forwarding” it in some requirements, depending on the specific situation. Paying attention to this kind of specific terminology can save you a lot of guesswork.
SHOULD
Yep, SHOULD deserves its own section. This wishy-washy term plagues many RFCs, despite efforts to eradicate it. RFC2119 describes it as:

In practice, authors often use SHOULD and SHOULD NOT to mean “We’d like you to do this, but we know we can’t always require it.”
For example, in the overview of HTTP methods, we see:

These SHOULDs are not MUSTs because the server might reasonably decide to take another action; if the request is from a client that is believed to be an attacker, it might drop the connection, or if HTTP authentication is required for the resource, it might enforce that with a 401 (Not Authenticated) before getting to the 405.
SHOULD doesn’t mean that the server is free to ignore a requirement because it doesn’t feel like honouring it.
Sometimes, we see a SHOULD that follows this form:

Notice the “unless” – it’s specifying the “particular circumstances” that the SHOULD allows. Arguably this could be specified as a MUST, since the unless clause would still apply, but this style of specification is somewhat common.
Reading examples
Another very common pitfall is to skim the specification for examples, and implement what they do.
Unfortunately, examples typically get the least amount of attention from authors, since they need to be updated with each change to the protocol.
As a result, they’re very often the least reliable parts of the spec. Yes, the authors should absolutely double-check the examples before publication, but errors do slip through.
Also, even a perfect example might not be intended to illustrate the aspect of the protocol you’re looking for; they’re often truncated for brevity, or shown after an decoding step takes place.
Even though it takes more time, it’s better to read the actual text; examples are not the specification.
On ABNF
Augmented BNF is often used to define protocol artefacts. For example:

Once you get used to it, ABNF offers an easy-to-understand sketch of what protocol elements should look like.
However, ABNF is “aspirational” - it identifies an ideal form for a message, and those messages that you generate really need to match it. It doesn’t specify what to do with received messages that fail to match it. In fact, many specifications fail to say what the relationship of ABNF is to processing requirements at all.
Most protocols will fail badly if you try to enforce their ABNF strictly, but sometimes it matters. In the example above, whitespace isn’t allowed around the semicolon, but you can bet that some people will put it there, and some implementations will accept it.
So, make sure you read the text around the ABNF for additional requirements or context, and realise that absent a direct requirement, you may have to adjust parsing to be more accepting of input than the ABNF implies.
Some specifications are starting to acknowledge the aspirational nature of ABNF and specifying explicit parsing algorithms that incorporate error handling. When specified, these should be followed exactly, to ensure interoperability.
Security considerations
Ever since RFC3552, the RFC boilerplate has included a “Security Considerations” section.
As a result, it’s rare for an RFC to be published without a substantial section on security; the review process does not allow a draft to just say “There are no security considerations for this protocol”.
So, it pays to read and make sure you understand the Security Considerations section, whether you’re implementing or deploying the protocol; if you don’t, it’s very likely that something will bite you down the road.
Following its references (if any) is also a good idea. If there aren’t any, try looking up some of the terms used to get an appreciation of the issues being discussed.
Finding out more
If an RFC doesn’t answer your question, or you’re not sure about the intent of its text, the best thing to do is to find the most relevant Working Group and ask a question on their mailing list. If there isn’t an active working group covering the topic in question, try the mailing list for the appropriate area.
Filing an errata is usually not the first step you should take – talk to someone first.
Many Working Groups are now using Github for managing their specifications; if you have a question about an active specification, go ahead and file an issue. If it’s already an RFC, it’s usually best to use the mailing list unless you find directions to the contrary.
I’m sure there’s more to write about how to read RFCs, and some will dispute what I’ve written here, but this is how I think about them. I hope it was useful.