Filter by topic and date
The Blind Men and the Elephant
10 Feb 2018
Bufferbloat is responsible for much of the poor performance seen in the Internet today and causes latency (called “lag” by gamers) even by your own routine web browsing and video playing.

But bufferbloat’s causes and solutions remind me of the old parable:
It was six men of Indostan, to learning much inclined,
who went to see the elephant (Though all of them were blind),
that each by observation, might satisfy his mind.
……. (six stanzas elided)
And so these men of Indostan, disputed loud and long,
each in his own opinion, exceeding stiff and strong,
Though each was partly in the right, and all were in the wrong!
So, oft in theologic wars, the disputants, I ween,
tread on in utter ignorance, of what each other mean,
and prate about the elephant, not one of them has seen!
John Godfrey Saxe
Most technologists are not truly wise: we are usually like the blind men of Indostan. The TCP experts, network operators, telecom operators, router makers, Internet service operators, router vendors and users have all had a grip only on their piece of the elephant.
The TCP experts look at TCP and think “if only TCP were changed” in their favorite way, all latency problems would be solved, forgetting that there are many other causes of saturating an Internet link, and that changing every TCP implementation on the planet will take time measured in decades. With the speed of today’s processors, almost everything can potentially transmit at gigabits per second. Saturated (“congested”) links are *normal* operation in the Internet, not abnormal. And indeed, improved congestion avoidance algorithms such as BBR and mark/drop algorithms such as CoDel and PIE are part of the solution to bufferbloat.
And since TCP is innately “unfair” to flows with different RTT’s, and we have both nearby (~10ms) or (inter)continental distant (~75-200ms) services, no TCP only solution can possibly provide good service. This is a particularly acute problem for people living in remote locations in the world who have great inherent latency differences between local and non-local services. But TCP only solutions cannot solve other problems causing unnecessary latency, and can never achieve really good latency as the queue they build depend on the round trip time (RTT) of the flows.
Network operators often think: “if only I can increase the network bandwidth,” they can banish bufferbloat: but at best, they can only move the bottleneck’s location and that bottleneck’s buffering may even be worse! When my ISP increased the bandwidth to my house several years ago (at no cost, without warning me), they made my service much worse, not better, as the usual bottleneck moved from the broadband link (where I had bufferbloat controlled using SQM) to WiFi in my home router. Suddenly, my typical lag became worse by more than a factor of ten, without having touched anything I owned and having double the bandwidth!
The logical conclusion of solving bufferbloat this way would be to build an ultimately uneconomic and impossible-to-build Internet where each hop is at least as fast as the previous link under all circumstances, and which ultimately collides with the limits of wireless bandwidth available at the edge of the Internet. Here lies madness. Today, we often pay for much more bandwidth than needed for our broadband connections just to reduce bufferbloat’s effects; most applications are more sensitive to latency than bandwidth, and we often see serious bufferbloat issues at peering points as well in the last mile, at home and using cellular systems. Unnecessary latency just hurts everyone.
Internet service operators optimize the experience of their applications to users, but seldom stop to see if the their service damages that of other Internet services and applications. Having a great TV experience, at the cost of good phone or video conversations with others is not a good trade-off.
Telecom operators, have often tried to limit bufferbloat damage by hacking the congestion window of TCP, which does not provides low latency, nor does it prevents severe bufferbloat in their systems when they are loaded or the station remote.
Some packets are much more important to deliver quickly, so as to enable timely behavior of applications. These include ACKS, TCP opens, TLS handshakes, and many other packet types such as VOIP, DHCP and DNS lookups. Applications cannot make progress until those responses return. Web browsing and other interactive applications suffer greatly if you ignore this reality. Some network operation experts have developed complex packet classification algorithms to try to send these packets on their way quickly.
Router manufacturers often have extremely complex packet classification rules and user interfaces, that no sane person can possibly understand. How many of you have successfully configured your home router QOS page, without losing hair from your head.
Lastly, packet networks are inherently bursty, and these packet bursts cause “jitter.” With only First In First Out (FIFO) queuing, bursts of tens or hundreds of packets happen frequently. You don’t want your VOIP packet or other time sensitive to be arbitrarily delayed by “head of line” blocking of bursts of packets in other flows. Attacking the right problem is essential.
We must look to solve all of these problems at once, not just individual aspects of the bufferbloat elephant. Flow Queuing CoDel (FQ_CoDel) is the first, but will not be the last such algorithm. And we must attack bufferbloat however it appears.
Flow Queuing Codel Algorithm: FQ_CoDel
Kathleen Nichols and Van Jacobson invented the CoDel Algorithm (described now formally in RFC 8289), which represents a fundamental advance in Active Queue Management that preceded it, which required careful tuning and could hurt you if not tuned properly. Their recent blog entry helps explain its importance further. CoDel is based on the notion of sojourn time, the time that a packet is in the queue, and drops packets at the head of the queue (rather than tail or random drop). Since the CoDel algorithm is independent of queue length, is self tuning, and is solely dependent on sojourn time, additional combined algorithms become not possible with predecessors such as RED.
Dave Täht had been experimenting with Paul McKenney's Stochastic Fair Queuing algorithm (SFQ) as part of his work on bufferbloat, confirming that many of the issues are caused by head of line blocking (and unfairness of differing RTTs of competing flows) were well handled by that algorithm.
CoDel and Daves and Pauls work inspired Eric Dumazet to invent the FQ_Codel algorithm almost immediately after the CoDel algorithm became available. Note we refer to it as Flow Queuing rather than Fair Queuing as it is definitely unfair in certain respects rather than a true Fair Queuing algorithm,
Synopsis of the FQ_Codel Algorithm Itself
FQ_CoDel, documented in RFC 8290, uses a hash (typically but not limited of the usual 5-tuple identifying a flow), and establishes a queue for each, as does the Stochastic Fair Queuing (SFQ) algorithm. The hash bounds memory usage of the algorithm enabling use on even small embedded router or in hardware. The number of hash buckets (flows) and what constitutes a flow can be adjusted as needed; in practice the flows are independent TCP flows.
There are two sets of flow queues: those flows which have built a queue, and queues for new flows.
The packet scheduler preferentially schedules packets from flows that have not built a queue from those which have built a queue (with provisions to ensure that flows that have built queues cannot be starved, and continue to make progress).
If a flow’s queue empties, and packets again appear later, that flow is considered a new flow again.
Since CoDel only depends on the time in queue, it is easily applied in FQ_CoDel to ensure that TCP flows are properly policed to keep their behavior from building large queues.
CoDel does not require tuning and works over a very wide range of bandwidth and traffic. Combining flow queuing with a older mark/drop algorithm is impossible with older AQM algorithms such as Random Early Detection (RED) which depend on queue length rather than time in queue, and require tuning. Without some mark/drop algorithm such as CoDel, individual flows might fill their FQ_CoDel queues, and while they would not affect other flows, those flows would still suffer bufferbloat.
What Effects Does the FQ_CoDel Algorithm Have?
FQ_Codel has a number of wonderful properties for such a simple algorithm:
- Simple “request/response” or time based protocols are preferentially scheduled relative to bulk data transport. This means that your VOIP packets, your TCP handshakes, cryptographic associations, your button press in your game, your DHCP or other basic network protocols all get preferential service without the complexity of extensive packet classification, even under very heavy load of other ongoing flows. Your phone call can work well despite large downloads or video use.
- Dramatically improved service for time sensitive protocols, since ACKS, TCP opens, security associations, DNS lookups, etc., fly through the bottleneck link.
- Idle applications get immediate service as they return from their idle to active state. This is often due to interactive user’s actions and enabling rapid restart of such flows is preferable to ongoing, time insensitive bulk data transfer.
- Many/most applications put their most essential information in the first data packets after a connection opens: FQ_CoDel sees that these first packets are quickly forwarded. For example, web browsers need the size information included in an image before being able to complete page layout; this information is typically contained in the first packet of the image. Most later packets in a large flow have less critical time requirements than the first packet(s).
- Your web browsing is significantly faster, particularly when you share your home connection with others, since head of line blocking is no longer such an issue.
- Flows that are “well behaved” and do not use more than their share of the available bandwidth at the bottleneck are rewarded for their good citizenship. This provides a positive incentive for good behavior (which the packet pacing work at Google has been exploiting with BBR, for example, which depends on pacing packets). Unpaced packet bursts are poison to “jitter”, that is the variance of latency, which sets how close to real time other algorithms (such as VOIP) need to operate.
- If there are bulk data flows of differing RTT’s, the algorithm ensures (in the limit) fairness between the flows, solving an issue that cannot itself be solved by TCP.
- User simplicity: without complex packet classification schemes, FQ_CoDel schedules packets far better than previous rigid classification systems.
- FQ_CoDel is extremely small, simple and fast and scalable both up and down in bandwidth and # of flows, and down onto very constrained systems. It is safe for FQ_CoDel to be “always on”.
Having an algorithm that “just works” for 99% of cases and attacks the real problem is a huge advantage and simplification. Packet classification need only be used only to provide guarantees when essential, rather than be used to work around bufferbloat. No (sane) human can possibly successfully configure the QOS page found on today’s home router. Once bufferbloat is removed and flow queuing present, any classification rule set can be tremendously simplified and understood.
Limitations and Warnings
If flow queuing AQM is not present at your bottleneck in your path, nothing you do can save you under load. You can at most move the bottleneck by inserting an artificial bottleneck.
The FQ_CoDel algorithm [RFC 8290], particularly as a queue discipline, is not a panacea for bufferbloat as buffers hide all over today's systems. There have been about a dozen significant improvements to reduce bufferbloat just in Linux starting with Tom Herbert's Linux BQL , Eric Dumazet's TCP Small queues, TSO Sizing and FQ scheduler, just naming a few. Our thanks to everyone in the Linux community for their efforts. FQ_Codel, implemented in its generic form as the Linux queue discipline fq_codel, only solves part of the bufferbloat problem, that found in the qdisc layer. The FQ_CoDel algorithm itself is applicable to a wide variety of circumstances, and not just in networking gear, but even sometimes in applications.
WiFi and Wireless
Good examples of the buffering problems occurs in wireless and other technologies such as DOCSIS and DSL. WiFi is particularly hard: rapid bandwidth variation and packet aggregation means that WiFi drivers must have significant internal buffering. Cellular systems have similar (and different) challenges.
Toke Høiland-Jørgensen, Michał Kazior, Dave Täht, Per Hertig and Anna Brunstrom reported amazing improvements for WiFi at the Usenix Technical Conference. Here, FQ_CoDel algorithm is but part of a more complex algorithm that handles aggregation and transmission air-time fairness (which Linux has heretofore lacked). The results are stunning, and we hope to see similar improvements in other technologies by applying FQ_Codel.
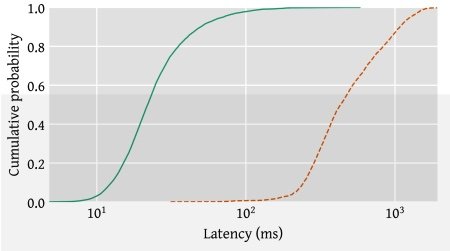
This chart shows the latency under load in milliseconds of the new WiFi algorithm, beginning adoption in Linux. The log graph is used to enable plotting results on the same graph. The green curve is for the new driver latency under load (cumulative probability of the latency observed by packets) while the orange graph is for the previous Linux driver implementation. You seldom see 1-2 orders of magnitude improvements in anything. Note that latency can exceed one second under load with existing drivers. And implementation of air-time fairness in this algorithm also significantly increases the total bandwidth available in a busy WiFi network, by using the spectrum more efficiently, while delivering this result! See the above paper for more details and data.
This new driver structure and algorithm is in the process of adoption in Linux, though most drivers do not yet take advantage of what this offers. You should demand your device vendors using Linux update their drivers to the new framework.
While the details may vary for different technologies, we hope the WiFi work will help illuminate techniques appropriate for applying FQ_CoDel (or other flow queuing algorithms, as appropriate) to other technologies such as cellular networks.
Performance and Comparison to Other Work
In the implementations available in Linux, FQ_CoDel has seriously outperformed all comers, as shown in: "The Good, the Bad and the WiFi: Modern AQMs in a residential setting," by Toke Høiland-Jørgensen, Per Hurtig and Anna Brunstrom. This paper is unique(?) in that it compares the algorithms consistently using the identical tests on all algorithms on the same up to date test hardware and software version, and is an apple-to-apple comparison of running code.
Our favorite benchmark for "latency under load" is the "rrul" test from Toke's flent test tool. It demonstrates when flow(s) may be damaging the latency of other flow(s) as well as goodput and latency. Low bandwidth performance is more difficult than high bandwidth. At 1Mbps, a single 1500 byte packet represents 12 milliseconds! This shows fq_codel outperforming all comers in latency, while preserving very high goodput for the available bandwidth. The combination of an effective self adjusting mark/drop algorithm with flow queuing is impossible to beat. The following graph measures goodput versus latency for a number of queue disciplines, at two different bandwidths, of 1 and 10Mbps (not atypical of the low end of WiFi or DSL performance). See the paper for more details and results.
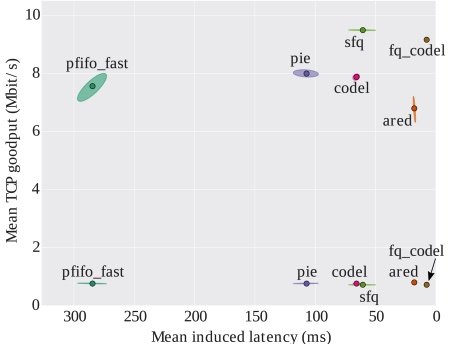
FQ_CoDel radically outperforms CoDel, while solving problems that no conventional TCP mark/drop algorithm can do by itself. The combination of flow queuing with CoDel is a killer improvement, and improves the behavior of CoDel (or PIE), since ACKS are not delayed.
Pfifo_fast previously has been the default queue discipline in Linux (and similar queuing is used on other operating systems): it is for the purposes of this test, a simple FIFO queue. Note that the default length of the FIFO queue is usually ten times longer than that displayed here in most of today’s operating systems. The FIFO queue length here was chosen so that the differences between algorithms would remain easily visible on the same linear plot!
Other self tuning TCP congestion avoidance mark/drop algorithms such as PIE [RFC 8033] are becoming available, and some of those are beginning to be combined with flow queuing to good effect. As you see above, PIE without flow queuing is not competitive (nor is CoDel). An FQ-PIE algorithm, recently implemented for FreeBSD by Rasool Al-Saadi and Grenville Armitage, is more interesting and promising. Again, flow queuing combined with an auto-adjusting mark/drop algorithm is the key to FQ-PIE’s behavior.
Availability of Modern AQM Algorithms
Implementations of both CoDel and FQ_Codel were released in Linux 3.5 in July 2012 and in FreeBSD 11, in October, 2016 (and backported to FreeBSD 10.3); FQ-PIE is only available in FreeBSD (though preliminary patches for Linux exist).
FQ_CoDel has seen extensive testing, deployment and use in Linux since its initial release. There is never a reason to use CoDel, and is present in Linux solely to enable convenient performance comparisons, as in the above results. FQ_CoDel first saw wide use and deployment as part of OpenWrt when it became the default queue discipline there, and used heavily as part of the SQM (Smart Queue Management) system to mitigate last mile bufferbloat. FQ_CoDel is now the default queue discipline on most Linux distributions in many circumstances. FQ_CoDel is being used in an increasing number of commercial products.
The FQ_CoDel based WiFi improvements shown here are available in the latest OpenWrt release for a few chips. WiFi chip vendors and router vendors take note: your competitors may be about to pummel you, as this radical improvement is now becoming available.
PIE, but not FQ-PIE, was mandated in DOCSIS 3.1, and is much less effective than FQ_CoDel (or FQ-PIE).
Continuing Work: CAKE
Research in other AQMs continue apace. FQ_CoDel and FQ-PIE are far from the last words on the topic.
Rate limiting is necessary to mitigate bufferbloat in equipment that has no effective queue management (such as most existing DSL or most Cable modems). While we have used fq_codel in concert with Hierarchical Token Bucket (HTB) rate limiting for years as part of the Smart Queue Management (SQM) scripts (in OpenWrt and elsewhere), one can go further in an integrated queue discipline to address problems difficult to solve piecemeal, and make configuration radically simpler. The CAKE queue discipline, available today in OpenWrt, additionally adds integrated framing compensation, diffserv support and CoDel improvements. We hope to see CAKE upstream in Linux soon. Please come help in its testing and development.
As you see above, the Make WiFi Fast project is making headway and makes WiFi much to be preferred to cellular service when available, much, much more is left to be done. Investigating fixing bufferbloat in WiFi made us aware of just how much additional improvement in WiFi was also possible. Please come help!
Conclusion
Ye men of Indostan, to learning much inclined, see the elephant, by opening your eyes:
ISP’s, insist your equipment manufacturers support modern flow queuing automatic queue management. Chip manufacturers: ensure your chips implement best practices in the area, or see your competitors win business.
Gamers, stock traders, musicians, and anyone wanting decent telephone or video calls take note. Insist your ISP fix bufferbloat in its network. Linux and RFC 8290 prove you can have your cake and eat it too. Stop suffering.
Insist on up to date flow queuing queue management in devices you buy and use, and insist that bufferbloat be fixed everywhere.